[System Design] Indexes
Mục lục
- Phần 1: Các tính chất chính của một hệ thống phân tán
- Phần 2: Cân bằng tải (Load Balancing)
- Phần 3: Bộ đệm — Caching
- Phần 4: Phân chia dữ liệu — Sharding/Data Partitioning
- Phần 5: Indexes
- Phần 6: Proxies
- Phần 7: Sao lưu và đồng bộ dữ liệu — Redundancy and Replication
- Phần 8: SQL vs. NoSQL
- Phần 9: Định lý CAP / CAP Theorem
- Phần 10: Consistent Hashing
- Phần 11: Long-Polling vs WebSockets vs Server-Sent Events
Phần 5: Indexes
Đánh Index trong Cơ Sở Dữ Liệu
Có lẽ thuật ngữ “đánh index” đã quá quen với những ai làm việc với Cơ Sở Dữ Liệu (CSDL), đó là cách rất phổ biến để tăng tốc độ truy vấn dữ liệu. Khi dữ liệu trong cơ sở dữ liệu ngày càng tăng và trở nên chậm dần theo thời gian, tạo Index trở thành một mục tiêu quan trọng để cải thiện hiệu suất trả về dữ liệu.
Ý Nghĩa của Index
Mục tiêu của việc tạo Index là tăng tốc độ trả về dữ liệu của một hoặc nhiều trường (rows) trên một bảng (table) cụ thể bằng cách tạo Index trên một hoặc nhiều cột (columns) của một bảng cơ sở dữ liệu.
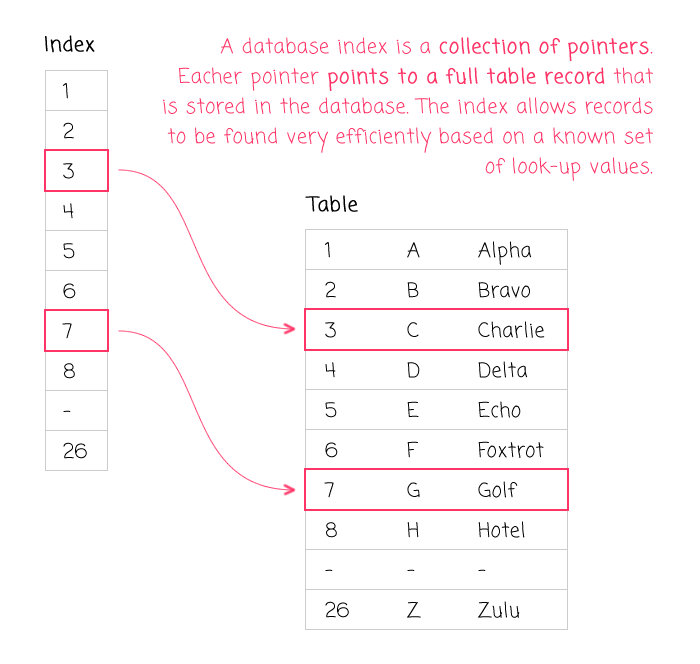
Giải Thích bằng Ví Dụ
Để hiểu rõ hơn thế nào là Indexes ta hãy đến thử một nhà sách hay thư viện, thường các cuốn sách sẽ được phân chia theo các danh mục về nội dung như: sách nấu ăn, sách tiểu thuyết nước ngoài, sách tâm lý, sách lịch sử … Nếu ta muốn tìm kiếm một loại sách theo nội dung mong muốn thì chỉ việc tới cá kệ sách với nội dung tương ứng, nó sẽ nhanh hơn là tìm kiếm từ toàn bộ cả nhà sách từ. Hoặc ví dụ khác về các phần mục lục trong muốn cuốn sách, nếu ta muốn tìm nhanh đến “chương hồi” ta đang cần tìm kiếm hoặc đọc dở chỉ cần tra mục lục rồi tìm tới đúng trang chứa nội dung.
Index trong Database cũng giống như vậy, ví dụ ta có một table là Books chứa 4 columns là “book_title”, “writer”, “subject”, và “date_of_publication”, thường thì khách hàng sẽ thường xuyên tìm kiếm sách theo hai tiêu chí là tên sách và tác giả, do đó ta sẽ tạo Index cho hai column là “book_title” và “writer”. Database sẽ tạo ra một data structure riêng biệt chứa hai giá trị của toàn bộ nội dung (content) các cột đánh index và một con trỏ (pointer) để trỏ tới dữ liệu thật sự đang nằm ở Database. Như vậy, sử dụng index yêu cầu cần disk space để chứa cấu trúc của nó và Index cũng không làm thay đổi cấu trúc của table. Do vậy mỗi làm tìm kiếm dữ liệu thì Database sẽ tìm kiếm ở Index sau đó dựa vào con trỏ của Index để trả về dữ liệu thật.
Cách Hoạt Động của Index
Nhưng tại sao tìm kiếm trên Index lại nhanh hơn tìm kiếm trên Database, bởi vì Index luôn luôn sắp xếp dữ liệu để tối ưu nhất cho các thuật toán thực hiện việc tìm kiếm, còn dữ liệu Database thật thì luôn sắp xếp lộn xộn không có thứ tự nên không thuận tiện cho việc tìm kiếm. Mỗi Database sẽ có cách sắp xếp Index và thuật toán tìm kiếm Index khác nhau.
Tại Sao Index Nhanh Hơn
Tìm kiếm trên Index nhanh hơn so với tìm kiếm trên cơ sở dữ liệu vì Index luôn được sắp xếp tối ưu cho các thuật toán tìm kiếm. Ngược lại, dữ liệu trong cơ sở dữ liệu thường không được sắp xếp và có thứ tự.
Cẩn Trọng Khi Sử Dụng Index
Tuy nhiên, việc đánh Index cần cẩn trọng vì:
- Tạo Index tốn disk space, nên chỉ nên áp dụng cho các cột có dung lượng nhỏ.
- Việc tạo Index trên dữ liệu lớn sau khi đã có dữ liệu sẽ tốn thời gian và tài nguyên hệ thống.
- Cập nhật dữ liệu thường xuyên cũng ảnh hưởng đến hiệu suất của Index.
Kết Luận
Index không phải là một magic keyword và cần được sử dụng một cách cẩn trọng. Mục tiêu chính của Index là tăng khả năng đọc (read) của dữ liệu. Việc xem xét và xóa những Index không cần thiết là quan trọng, đặc biệt đối với các bảng mà thường xuyên ghi dữ liệu nhưng ít khi đọc.